

Overview
In the last tutorial, we covered how to build a 32-bit x86 Hello World program in NASM. Today, we will cover how to do the same thing, but this time using the GAS toolchain instead. This will allow us to review the differences in the source code syntax and structure, as well as the difference in the build process.
Prerequisite Knowledge
Before continuing, this article will assume you have some basic knowledge of the X86 architecture. A blog post that covers the basics of the X86 architecture can be found on our blogs. Since we will also be reproducing the exact same work we did in NASM, but with a different toolchain, it would be highly recommended to read that tutorial, which can be found in our blog pages. The reason you should read that one is this blog post will assume you understand the syscall and instruction concepts that were explained in that article to reduce the length of this tutorial. We will also be adding to the Makefile from that project to build the GAS version, along with the C and NASM versions from that tutorial. Since this is all bundled together, we have added these code samples to the Secure Ideas Professionally Evil GitHub repository which can be found on GitHub.
Source Code
Like last time with our NASM example, let's first list our complete code here for the hello_world_gas.s file, then we will pick it apart to explain what is going on. Also notice I've used a .s extension rather than a .asm extension on the filename. This can help with syntax highlighting to be correct in editors like nano. GAS typically uses .s as the extension and NASM uses the .asm and most syntax highlighting editors adjust based on that extension, since these two have different syntax. The complete code is as follows:
##########################################################################
#
# Program: hello_world_gas
#
# Date: 04/22/2021
#
# Author: Travis Phillips
#
# Purpose: A simple hello world program in x86 assembly for
# GAS
#
# Compile: as --march=i386 --32 ./hello_world_gas.s -o hello_world_gas.o
# Link: ld -m elf_i386 hello_world_gas.o -o hello_world_gas
#
##########################################################################
.global _start # we must export the entry point to the
# ELF linker or loader. Conventionally,
# they recognize _start as their entry
# point but this can be overridden with
# ld -e "label_name" when linking.
.data # .data section declaration
msg:
.ascii "Hello, World!\n" # Declare a label "msg" which has
# our string we want to print.
len = . - msg # "len" will calculate the current
# offset minus the "msg" offset.
# this should give us the size of
# "msg".
.text # .text section declaration
_start:
######################################
# syscall - write(1, msg, len);
######################################
mov $4,%eax # 4 = Syscall number for Write()
mov $1,%ebx # File Descriptor to write to
# In this case: STDOUT is 1
mov $msg,%ecx # String to write. A pointer to
# the variable 'msg'
mov $len,%edx # The length of string to print
# which is 14 characters
int $0x80 # Poke the kernel and tell it to run the
# write() call we set up
######################################
# syscall - exit(0);
######################################
mov $1,%al # 1 = Syscall for Exit()
mov $0,%ebx # The status code we want to provide.
int $0x80 # Poke kernel. This will end the program.
The code above might look massive, but much like the NASM example, it's mostly comments to help explain things. If we remove the comments, the code part would simply be:
.global _start
.data
msg:
.ascii "Hello, World!\n"
len = . - msg
.text
_start:
mov $4,%eax
mov $1,%ebx
mov $msg,%ecx
mov $len,%edx
int $0x80
mov $1,%al
mov $0,%ebx
int $0x80
The first chunk of our source code file is a comments section. This is mostly just project information for us.
########################################################################## # # Program: hello_world_gas # # Date: 04/22/2021 # # Author: Travis Phillips # # Purpose: A simple hello world program in x86 assembly for # GAS # # Compile: as --march=i386 --32 ./hello_world_gas.s -o hello_world_gas.o # Link: ld -m elf_i386 hello_world_gas.o -o hello_world_gas # ##########################################################################
Nothing major here. In GAS, anything following a pound sign (#) is considered a comment. This top part of our file is just some basic information for humans that are looking at the file. It is worth noting that GAS also supports multi-line comment blocks in the /* */ format as well. To my knowledge, I don't believe NASM supports multi-line comment blocks. We could have used that for the top part if we wanted to, but six is half a dozen; same difference.
However, the next line that follows exports our _start label so the compiler will make it visible to the linker to use as an entry point. The lines responsible for that is as follows:
.global _start # we must export the entry point to the
# ELF linker or loader. Conventionally,
# they recognize _start as their entry
# point but this can be overridden with
# ld -e "label_name" when linking.
The main difference between GAS and NASM on this front is that we need to add a period in front of the global keyword. The rest of the line's syntax works the same.
After this is the line that marks the start of our .data section of the ELF binary. The syntax on this code is even more straightforward than NASM. You can omit the keyword "section" and just put the section name. This .data section we will use to store our variables.
.data # .data section declaration
In the data section, we will create the same two variables as the NASM example. The first one is "msg". The "msg:" part is actually creating this as a label. A label provides a means for us to access an offset with a friendly name, and the compiler will actually implement the real offsets at compile time. To create a label you place a string, which is the label's name at the start of a line, followed by a colon (:). As for declaring the data, in NASM we used the db keyword. However, in GAS we have a keyword .ascii for declaring strings! This is actually a little nicer since we can actually use the \n escape sequence rather than having to drop the hex code 0xa for it.
msg:
.ascii "Hello, World!\n" # Declare a label "msg" which has
# our string we want to print.
The second variable we declare in the .data section is "len". Take notice that it FOLLOWS the msg variable. This is important because this line is performing an offset calculation to determine the size by taking the len offset and subtracting the msg label offset. This would effectively give to the size of the data between the two offsets. You may have also noticed that len this time is not a label! GAS allows us to create variables. The period (.) means this current offset, then "- msg" subtracts the msg offset.
len = . - msg # "len" will calculate the current
# offset minus the "msg" offset.
# this should give us the size of
# "msg".
Now that those two variables are created, we can now end the .data section and start the .text section. This is straightforward as we just put the section name without the section keyword, and the _start label creation code is the same in both NASM and GAS.
.text # .text section declaration _start:
Now we can start writing the assembly code we want to execute. First we will start by looking over the chunk of code that creates and invokes the write syscall to print our hello world message:
######################################
# syscall - write(1, msg, len);
######################################
mov $4,%eax # 4 = Syscall number for Write()
mov $1,%ebx # File Descriptor to write to
# In this case: STDOUT is 1
mov $msg,%ecx # String to write. A pointer to
# the variable 'msg'
mov $len,%edx # The length of string to print
# which is 14 characters
int $0x80 # Poke the kernel and tell it to run the
# write() call we set up
The logic here and instructions are the same as they were in the NASM example. However you may have noticed that the operands after the mov instructions are flipped and formatted as Source=>Destination. NASM was the inverse of that ordering. The other difference here is that values have a symbol before them that signifies what we are referencing. For example, the dollar sign ($) before the numbers signals the compiler that the value that follows is an immediate value, while the percent sign (%) signals that the value is a register. Overall the code set up is the same as it was with NASM, move the syscall number into EAX, setup the required 3 parameters, and use INT $0x80, to invoke the syscall for write to get our Hello World message printed to the console on STDOUT.
We can move on to our next and final syscall of exit which is shown below:
######################################
# syscall - exit(0);
######################################
mov $1,%al # 1 = Syscall for Exit()
mov $0,%ebx # The status code we want to provide.
int $0x80 # Poke kernel. This will end the program.
The code here should look familiar since it's just MOV and INT instructions again, following the same changes we saw between NASM and GAS.
Compiling and Linking
The comment block at the top of the code explains how to compile and link this code. It's pretty straightforward with the following two commands. However, this time for compiling we will use the as command (short for assembler). We are also providing a few more switches to this command because this can assemble for several architectures in several bitness formats. Therefore, we will want to use the --march switch and explicitly tell it we are building for the i386 architecture and the --32 switch to let it know that we are building this as a 32-bit binary. GAS can produce a 64-bit binary as well without issues if you wanted to experiment with that, but note that this code will not work as 64-bit, and we don't want GAS to assume that's what we want:
$ as --march=i386 --32 ./hello_world_gas.s -o hello_world_gas.o $ ld -m elf_i386 hello_world_gas.o -o hello_world_gas
To make things even easier, we can add the following text to a Makefile and leverage the make command to build both the C and NASM projects for us.
all: hello_world_c hello_world_nasm hello_world_gas
hello_world_nasm:
@echo "\n\033[33;1mBuilding NASM Hello World\033[0m"
nasm -f elf hello_world_nasm.asm
ld -m elf_i386 hello_world_nasm.o -o hello_world_nasm
hello_world_c:
@echo "\n\033[33;1mBuilding C Hello World\033[0m"
gcc hello_world.c -o hello_world_c
hello_world_gas:
@echo "\n\033[33;1mBuilding GAS Hello World\033[0m"
as --march=i386 --32 ./hello_world_gas.s -o hello_world_gas.o
ld -m elf_i386 hello_world_gas.o -o hello_world_gas
clean:
@echo "\n\033[33;1mRemoving executables and object files\033[0m"
rm -f hello_world_c
rm -f hello_world_nasm hello_world_nasm.o
rm -f hello_world_gas hello_world_gas.o
With that Makefile in place, you can build all three; the C, NASM, and GAS versions by simply running the make command in the directory as shown below:
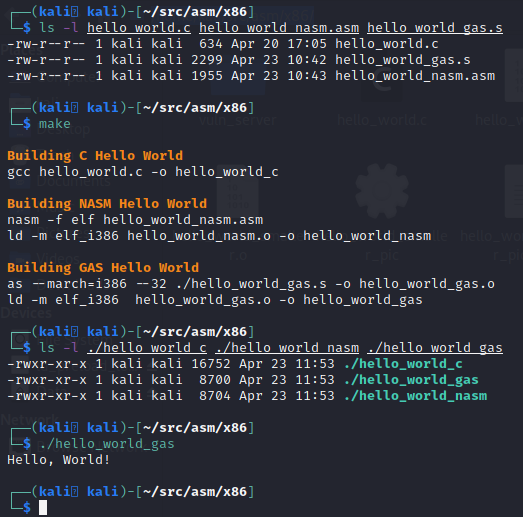
Advantages to Learning GAS
There are several reasons why GAS should be learned. GAS is more flexible than NASM, at a slightly steeper learning curve. However, GAS is multi-architecture where last I checked, NASM is strictly X86. GAS could do ARM, MIPS, PowerPC, SPARC and many others. Also since GAS and objdump are both GNU tools, the output of objdump much more closely resembles the code we wrote because the syntax is now the same between the two tools.
| What we wrote | What it became once compiled |
|---|---|
mov $4,%eax |
mov $0x4,%eax |
GAS also provides suffixes to instructions that can be used to specify the size of the data being moved. For example: MOVL would move a long value. MOVW would move a word value. MOVB would move a single byte. This can have a direct impact on the exported byte code.
Conclusion
I hope you've enjoyed this blog post and learned something new today about the x86 assembly in GAS. While these Hello World examples have worked well as a program, they do not work as a shellcode, at least not yet! In future posts, we will:
- Review our Hello World program
- Determine what issues impede its use as a shellcode payload
- What we can do to solve those problems
- Further reduce its size
- Write the asm file in a way that makes it easy to extract the bytecode for use as an exploit payload
- How to build a C shellcode tester stub and use it
If you're interested in security fundamentals, we have a Professionally Evil Fundamentals (PEF) channel that covers a variety of technology topics. We also answer general basic questions in our Knowledge Center.
Linux X86 Assembly Series Blog Post
Interested in more information about the X86 architecture and Linux shellcode/assembly? This blog is a part of a series and the full list of blogs in this series can be found below:
- A Hacker's Tour of the X86 CPU Architecture
- Linux X86 Assembly - How to Build a Hello World Program in NASM
- Linux X86 Assembly - How to Build a Hello World Program in GAS
- Linux X86 Assembly - How to Make Our Hello World Usable as an Exploit Payload
- Linux X86 Assembly - How To Make Payload Extraction Easier
- Linux X86 Assembly - How To Test Custom Shellcode Using a C Payload Tester
Assembly, shellcode, and exploit development. This is what our team does.
Low-level binary analysis and custom exploit development are part of how our consultants approach security assessments. If you have applications, firmware, or embedded devices that need testing, we can help.
Talk to Our Team